A guide to start using Flux
Flux
Table of Contents
Core Concepts
GitOps
GitOps is a way of managing your infrastructure and applications so that whole system is described declaratively and version controlled (most likely in a Git repository), and having an automated process that ensures that the deployed environment matches the state specified in a repository.
The core idea of GitOps is having a Git repository that always contains declarative descriptions of the infrastructure currently desired in the production environment and an automated process to make the production environment match the described state in the repository. If you want to deploy a new application or update an existing one, you only need to update the repository - the automated process handles everything else. It’s like having cruise control for managing your applications in production.
The Flux toolkit
Flux is constructed with the GitOps Toolkit components, which is a set of
- specialized tools and Flux Controllers
- composable APIs
- reusable Go packages for GitOps under the fluxcd GitHub organisation
for building Continuous Delivery on top of Kubernetes.” (Source: Taken from the Flux docs)
Below is a diagram that highlights how it all works together: 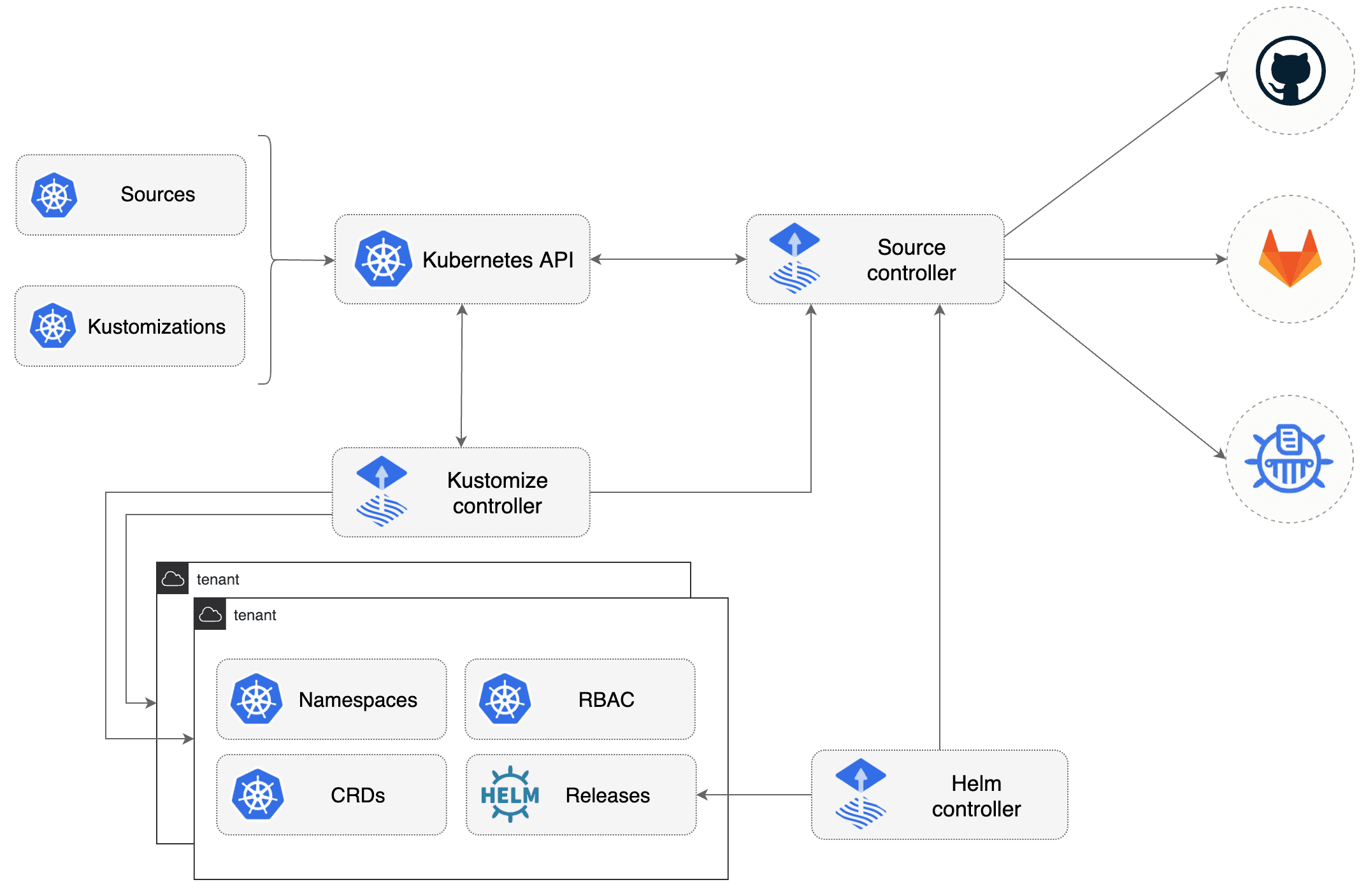
Push-based vs. Pull-based Deployments
There are two ways to implement the deployment strategy for GitOps: Push-based and Pull-based deployments. The difference between the two deployment types is how it is ensured, that the deployment environment actually resembles the desired infrastructure. When possible, the Pull-based approach should be preferred as it is considered the more secure and thus better practice to implement GitOps.
Push-based Deployments
The Push-based deployment strategy is implemented by popular CI/CD tools such as Jenkins, CircleCI, or Travis CI. The source code of the application lives inside the application repository along with the Kubernetes YAMLs needed to deploy the app. Whenever the application code is updated, the build pipeline is triggered, which builds the container images and finally the environment configuration repository is updated with new deployment descriptors.
Tip: You can also just store templates of the YAMLs in the application repository. When a new version is built, the template can be used to generate the YAML in the environment configuration repository.
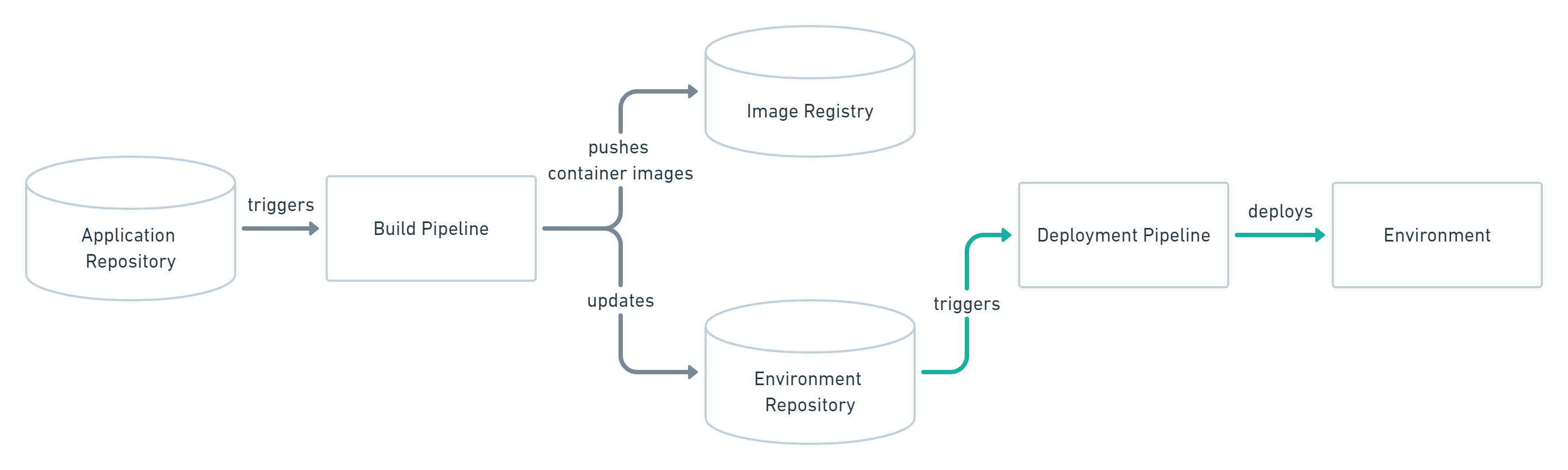
Changes to the environment configuration repository trigger the deployment pipeline. This pipeline is responsible for applying all manifests in the environment configuration repository to the infrastructure. With this approach it is indispensable to provide credentials to the deployment environment. So the pipeline has god-mode enabled. In some use cases a Push-based deployment is inevitable when running an automated provisioning of cloud infrastructure. In such cases it is strongly recommended to utilize the fine-granular configurable authorization system of the cloud provider for more restrictive deployment permissions.
Another important thing to keep in mind when using this approach is that the deployment pipeline only is triggered when the environment repository changes. It can not automatically notice any deviations of the environment and its desired state. This means, it needs some way of monitoring in place, so that one can intervene if the environment doesn’t match what is described in the environment repository.
Pull-based Deployments
The Pull-based deployment strategy uses the same concepts as the push-based variant but differs in how the deployment pipeline works. Traditional CI/CD pipelines are triggered by an external event, for example when new code is pushed to an application repository. With the pull-based deployment approach, the operator is introduced. It takes over the role of the pipeline by continuously comparing the desired state in the environment repository with the actual state in the deployed infrastructure. Whenever differences are noticed, the operator updates the infrastructure to match the environment repository. Additionally the image registry can be monitored to find new versions of images to deploy.
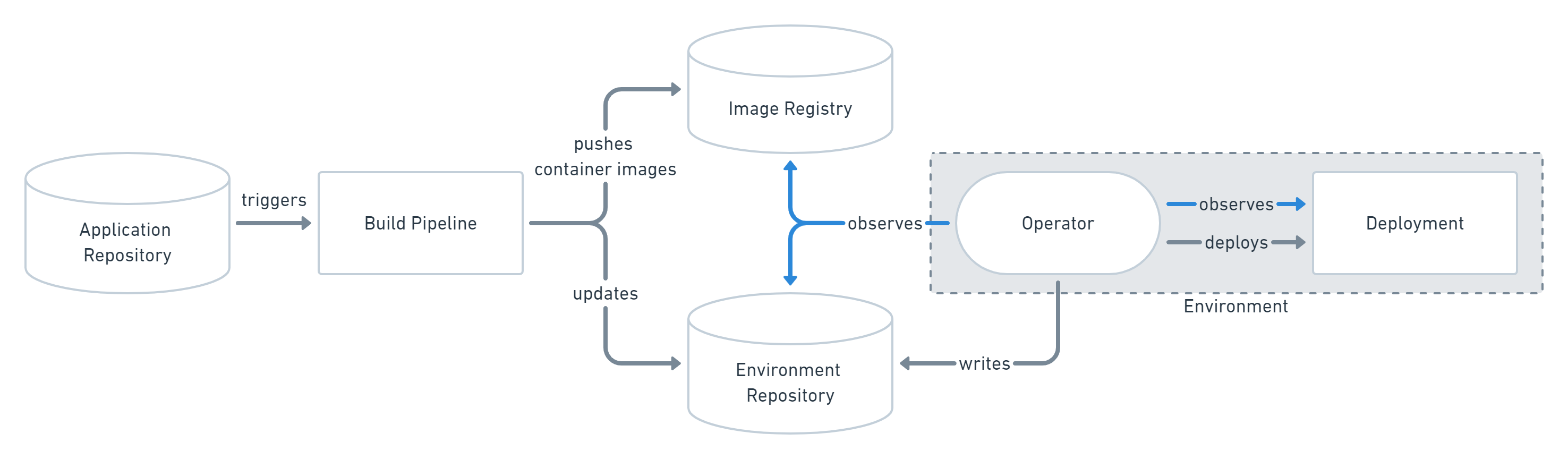
Just like the push-based deployment, this variant updates the environment whenever the environment repository changes. However, with the operator, changes can also be noticed in the other direction. Whenever the deployed infrastructure changes in any way not described in the environment repository, these changes are reverted. This ensures that all changes are made traceable in the Git log, by making all direct changes to the cluster impossible.
This change in direction solves the problem of push-based deployments, where the environment is only updated when the environment repository is updated. However, this doesn’t mean you can completely do without any monitoring in place. Most operators support sending mails or Slack notifications if it can not bring the environment to the desired state for any reason, for example if it can not pull a container image. Additionally, you probably should set up monitoring for the operator itself, as there is no longer any automated deployment process without it.
The operator should always live in the same environment or cluster as the application to deploy. This prevents the god-mode, seen with the push-based approach, where credentials for doing deployments are known by the CI/CD pipeline. When the actual deploying instance lives inside the very same environment, no credentials need to be known by external services. The Authorization mechanism of the deployment platform in use can be utilized to restrict the permissions on performing deployments. This has a huge impact in terms of security. When using Kubernetes, RBAC configurations and service accounts can be utilized.
Sources
A Source defines the origin of a repository containing the desired state of the system and the requirements to obtain it (e.g. credentials, version selectors). For example, the latest 1.x tag available from a Git repository over SSH.
Sources produce an artifact that is consumed by other Flux components to perform actions, like applying the contents of the artifact on the cluster. A source may be shared by multiple consumers to deduplicate configuration and/or storage.
The origin of the source is checked for changes on a defined interval, if there is a newer version available that matches the criteria, a new artifact is produced.
All sources are specified as Custom Resources in a Kubernetes cluster, examples of sources are GitRepository,OCIRepository, HelmRepository and Bucket resources.
Reconciliation
Reconciliation refers to ensuring that a given state (e.g. application running in the cluster, infrastructure) matches a desired state declaratively defined somewhere (e.g. a Git repository).
There are various examples of these in Flux:
HelmReleasereconciliation: ensures the state of the Helm release matches what is defined in the resource, performs a release if this is not the case (including revision changes of a HelmChart resource).Bucketreconciliation: downloads and archives the contents of the declared bucket on a given interval and stores this as an artifact, records the observed revision of the artifact and the artifact itself in the status of resource.Kustomizationreconciliation: ensures the state of the application deployed on a cluster matches the resources defined in a Git or OCI repository or S3 bucket.
Kustomization
The Kustomization custom resource represents a local set of Kubernetes resources (e.g. kustomize overlay) that Flux is supposed to reconcile in the cluster. The reconciliation runs every five minutes by default, but this can be changed with .spec.interval. If you make any changes to the cluster using kubectl edit/patch/delete, they will be promptly reverted. You either suspend the reconciliation or push your changes to a Git repository.
Bootstrap
The process of installing the Flux components in a GitOps manner is called a bootstrap. The manifests are applied to the cluster, a GitRepository and Kustomization are created for the Flux components, then the manifests are pushed to an existing Git repository (or a new one is created). Flux can manage itself just as it manages other resources. The bootstrap is done using the flux CLI or using our Terraform Provider.
Getting started with Flux
Firstly, install Flux Doc
Make sure to have your Git credentials:
export GITHUB_TOKEN=<your-token>
export GITHUB_USER=<your-username>
You can find the token within the following path https://github.com/settings/tokens
Next, ensure that you have access to your Kubernetes cluster through the CLI. I usually just check whether I have access to nodes:
kubectl get nodes
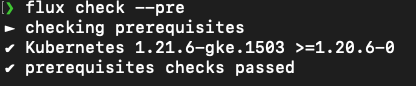
Then, check your cluster is compatible and ready for Flux:
flux check --pre
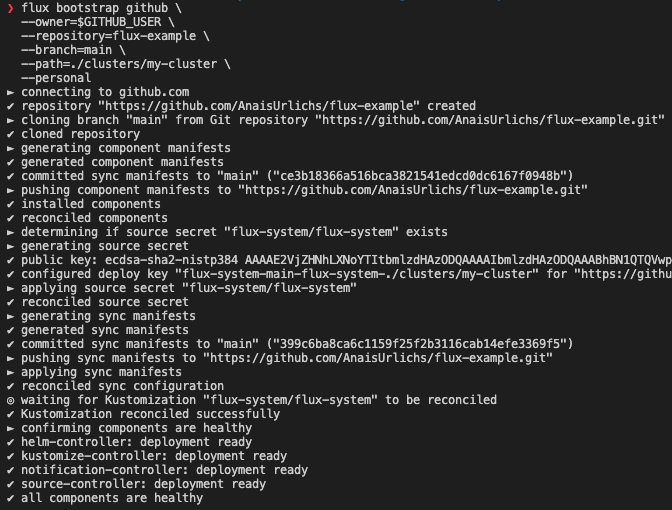
Next, we want to install Flux into our Kubernetes cluster, this is done with the Flux bootstrap command:
flux bootstrap github \\
--owner=$GITHUB_USER \\
--repository=flux-example \\
--branch=main \\
--path=./clusters/my-cluster \\
--personal
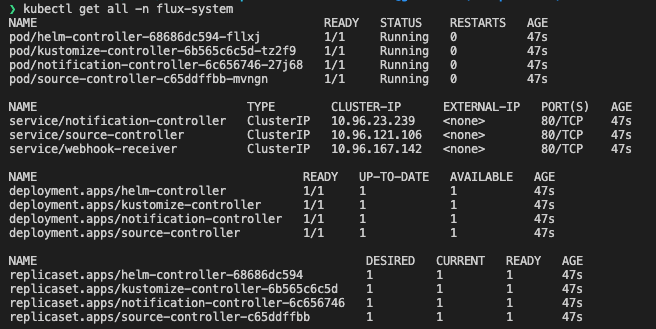
This will create a namespace inside of your Kubernetes cluster where all the Flux resources are going to be installed. Additionally, a Git repository will be created in your linked account.
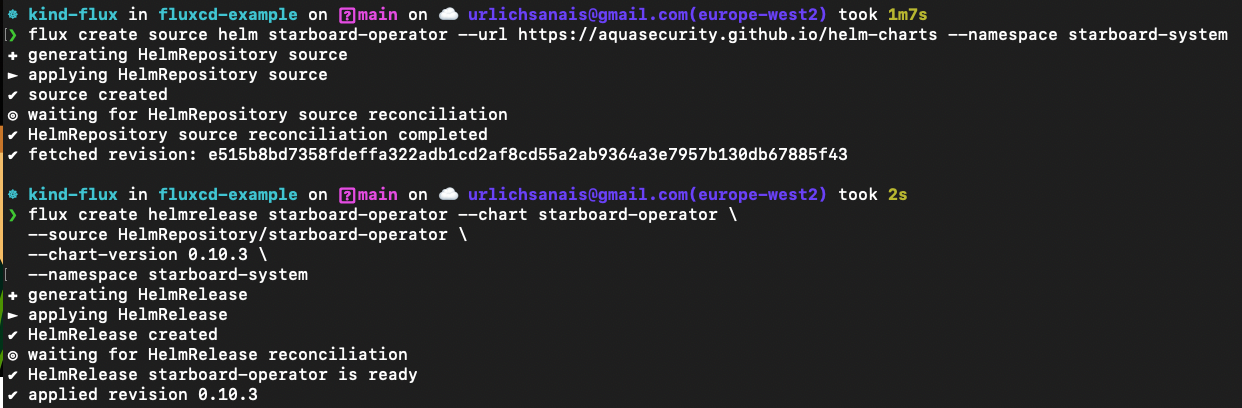
Installing the Starboard Helm Chart through Flux
Quick comment: 1 thing I really like about the Flux documentation is that it will show you the known way of doing things — for instance, if you want to deploy a Helm Chart, you will likely know how to deploy a Helm Chart without Flux. Thus, they show you that part first AND THEN they show you the new way for deploying the Helm Chart with Flux. This way, they build on your pre-existing schemas. Well done!
First, we need to create the namespace for Starboard
kubectl create ns starboard-system
Then we use the Flux client below, not the Helm client — the Helm client is just provided for reference in case you want to deploy a different Helm Chart.
- Helm client:
helm install starboard-operator aqua/starboard-operator \\
--namespace starboard-system \\
--create-namespace \\
--set="trivy.ignoreUnfixed=true" \\
--version 0.10.3
- Flux client:
flux create source helm starboard-operator --url <https://aquasecurity.github.io/helm-charts> --namespace starboard-system
flux create helmrelease starboard-operator --chart starboard-operator **\\**
--source HelmRepository/starboard-operator **\\**
--chart-version 0.10.3 **\\**
--namespace starboard-system
However, we can also install Starboard through Flux by deploying the following Kubernetes manifests:
apiVersion: source.toolkit.fluxcd.io/v1beta2
kind: HelmRepository
metadata:
name: starboard-operator
namespace: flux-system
spec:
interval: 1m0s
url: <https://aquasecurity.github.io/helm-charts/>
---
apiVersion: helm.toolkit.fluxcd.io/v2beta1
kind: HelmRelease
metadata:
name: starboard-operator
namespace: starboard-system
spec:
chart:
spec:
chart: starboard-operator
sourceRef:
kind: HelmRepository
name: starboard-operator
namespace: flux-system
version: 0.10.3
interval: 1m0s
and then we can apply the manifests through kubectl:
kubectl apply -f helm-starboard.yaml
Next, we are going to deploy an Application through Flux that our Starboard Operator will monitor.
Create an Application through Flux
We can ask Flux to manage our application. This can be done through several options, however, in this blog post, I am going to show you the imperative way and the declarative way.
The declarative way
The imperative way of telling Flux to install our resources is through their bootstrap command:
apiVersion: source.toolkit.fluxcd.io/v1beta2
kind: GitRepository
metadata:
name: react-app
namespace: flux-system
spec:
interval: 1m
url: <https://github.com/AnaisUrlichs/react-article-display>
ref:
branch: main
ignore: |
# exclude all
/*
# include charts directory
!/manifests/
---
apiVersion: kustomize.toolkit.fluxcd.io/v1beta2
kind: Kustomization
metadata:
name: react-app
namespace: flux-system
spec:
interval: 5m0s
path: ./manifests
prune: true
sourceRef:
kind: GitRepository
name: react-app
targetNamespace: app
This YAML manifest can then be deployed like any other Kubernetes resource:
kubectl apply -f ./application.yaml
The imperative Way
In the imperative way, we are first going to set up the repository for Flux:
flux create source git react \\
--url=https://github.com/AnaisUrlichs/react-article-display \\
--branch=main
and then we are going to deploy the application by telling Flux the path to our Kubernetes manifests inside of the repository and how we want Flux to manage the repository:
flux create kustomization react-app \\
--target-namespace=app \\
--source=react \\
--path="./manifests" \\
--prune=true \\
--interval=5m \\
Once set up, Starboard is already busy scanning not only our application but also our Flux-related resources for vulnerabilities:

I think Flux is doing pretty well, with only one High vulnerability. This gives me higher confidence in using Flux.